
The aim of this blog is to guide individuals in comprehending the methodology and tactics required to construct a web scraper.
The problem with low resource languages for NLP
When getting started with an NLP project, the initial bottleneck is always acquiring relevant data. This issue is magnified when trying to work on an NLP project for Indian languages. Some of the challenges associated with building an NLP project for languages with a low digital presence are as follows.
- Absence of Data: The absence of adequate data is the first problem. Digital text and audio data are frequently absent from low resource languages, making it difficult to train NLP algorithms. This reduces the amount of data that may be used for NLP system training, testing, and assessment.
- Lack of Pre-Trained Models: The absence of pre-trained models makes it more difficult to begin developing new models. Pre-trained models, which are often developed using enormous amounts of data, serve as a foundation for developing new models. Yet, such models might not exist or be too small for low resource languages to make a major impact.
- Language Complexity: Languages with limited resources are frequently more complex than their counterparts with abundant resources. They could lack standards in terms of spelling, grammar, or vocabulary, or they might have complex morphology or syntax.
- The restricted availability of linguistic resources, including dictionaries, grammars, and instruments for part-of-speech tagging and parsing, among other things, is another major issue. These tools are essential for developing NLP systems. Code-Mixing and Multilingualism: Low resource languages are often spoken in multilingual environments, leading to code-mixing or borrowing from other languages. This makes it challenging to develop models that can accurately capture the unique features of the language.
- Lack of Expertise: It takes specialist knowledge and experience to develop NLP solutions for languages with limited resources. This includes expertise in data science, computer learning, and languages. The availability of such knowledge, however, may be constrained, particularly in areas where the language is not frequently spoken or recognised.
While this is pretty depressing, we can start fixing it one line of code at a time :).

Choosing data sources
I’ve decided to focus on getting more data for Indian languages. More specifically I am focusing on Malayalam, which is my native language. The largest monolingual dataset that I have found for malayalam is the common crawl dataset. This might not be suitable for smaller projects as it is a collection of monthly scrapes of all internet data, in multiple languages.
So I decided to search for a smaller target, which led me to this website. This was a news website with a seperate section for archived data.This was a dream come true for a data nerd like me. All of this good, juicy data was just sitting there for the taking.

They had news articles saved all the way back to the year 2000!
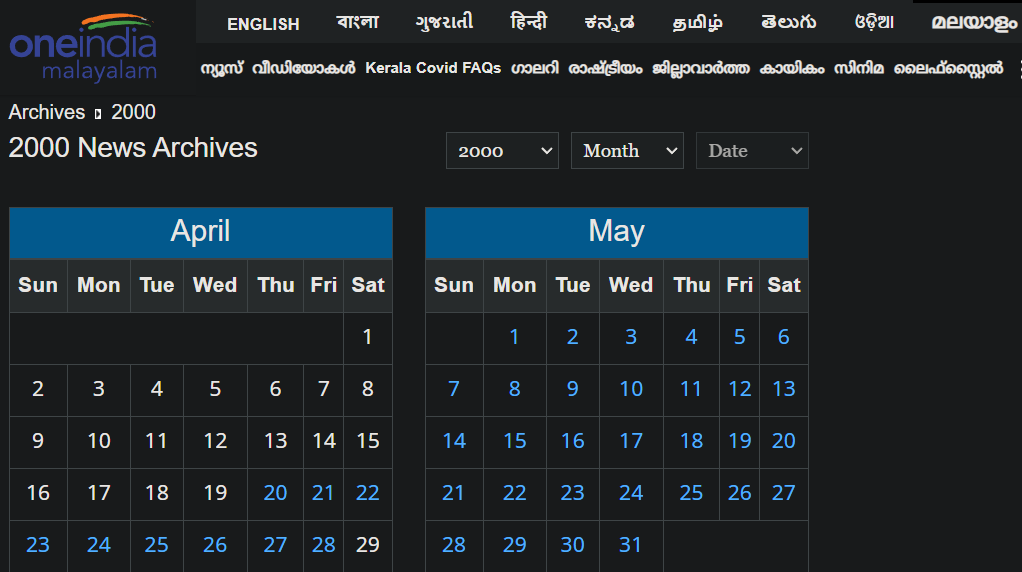
Lets get scraping
The first step in scraping any website is to analyze the structure of the website and what kind of data you would like to extract from it. We will be using beautiful soup, and use it to parse html files.
Install bs4 using pip
pip install beautifulsoup4
For this particular website, there was archived news data for 8 different languages. Each of their websites had urls similar to “https://<language>.oneindia.com/archives/” where “<language>” was replaced appropriately with one of the 8 languages.
The archives itself was built like a calendar widget, where you could select a date and view the news for that particular date.
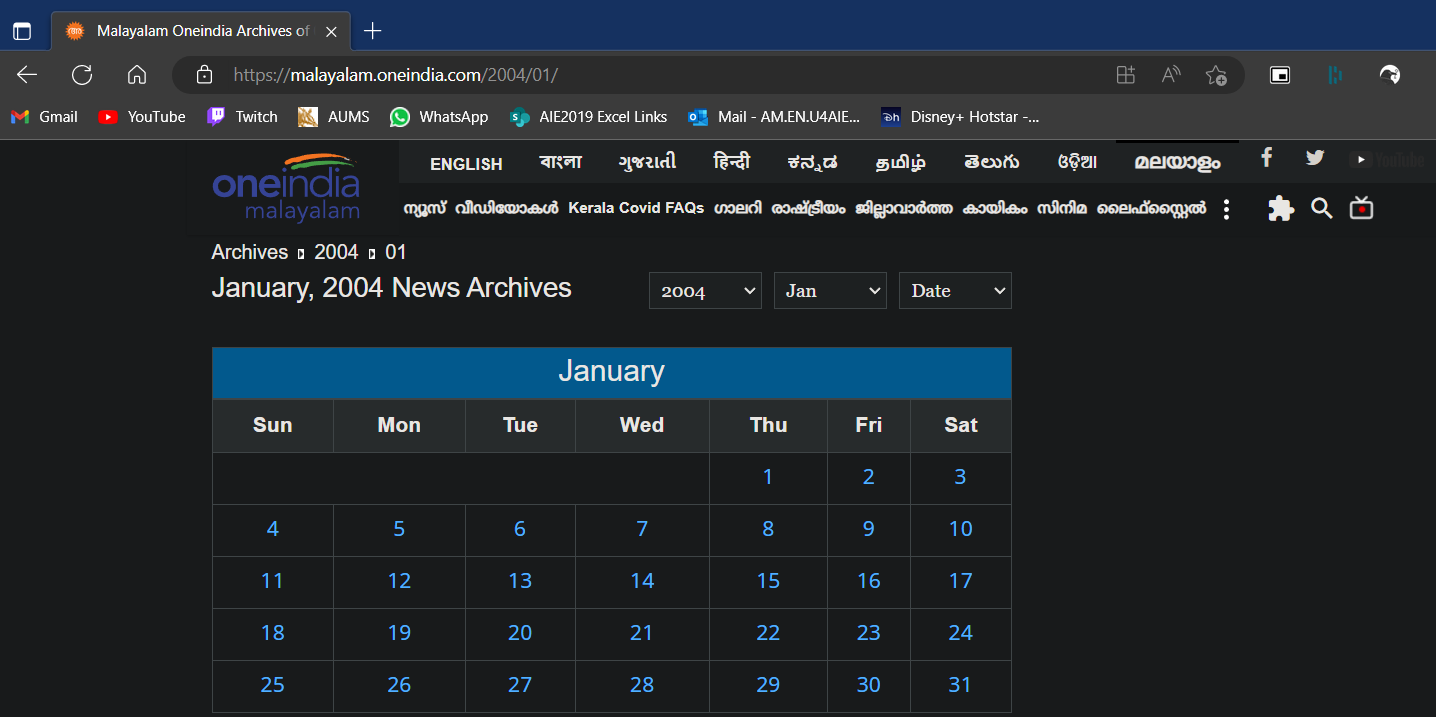
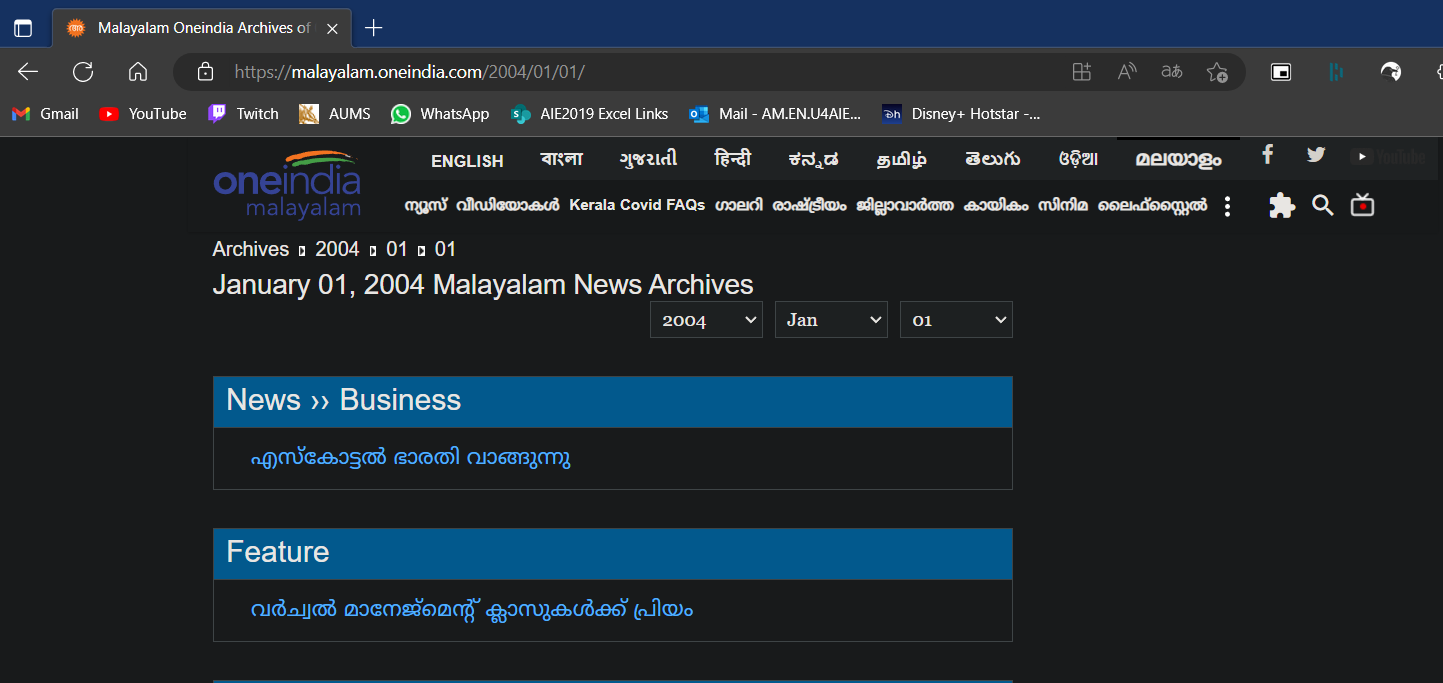
Notice the changes in the url when we get to the day view. The url “https://malayalam.oneindia.com/2004/01/01/” displays the archived malayalam news data for January 1st 2007. This honestly makes our job so much easier as all we really have to do is loop through all the date combinations from 2000/05/01 to the current date. So our scraping function begins to look like this.
def get_data(url, lang, save_dir):
url = url.replace("language", lang)
end_date = date.today()
start_date = date(2000, 5, 1)
data = []
for single_date in daterange(start_date, end_date):
url_end = single_date.strftime("%Y-%m-%d").replace("-", "/") + "/"
page_url = url + url_end
# scrape data from page_url and return it
get_data(url, args.lang, args.save_dir)
The next step is to find the url information of each news article in the list. We can use this to navigate to each article and then finally get our data.
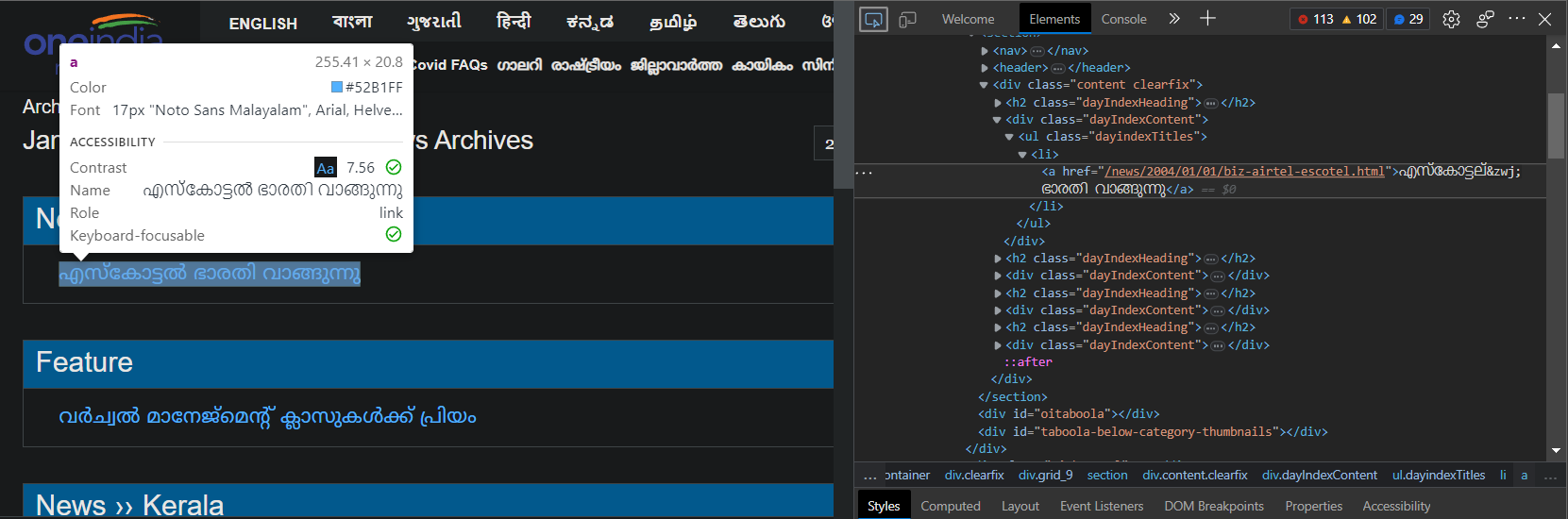
The built-in tools of our browser can help us in achieving this goal. Open developer tools to get a view of the html code displayed by the browser. Then using the inspect element tool, click on the news article. This highlights the code snippet relevant to the url.
page_html = requests.get(page_url).content
main_soup = BeautifulSoup(page_html, features="html5lib")
for elem in main_soup.findAll("ul", attrs={"class": "dayindexTitles"}):
news_url = url + elem.a.attrs["href"]
Our initial step involves invoking an HTML request to the previously acquired URL. The resultant HTML content is subsequently passed to the BeautifulSoup wrapper, which utilizes the ‘html5lib’ parser to construct a representation of the Document Object Model (DOM) of the page.
Then we use the findAll function of beautifulSoup to find all ul elements with the class value of “dayIndexTitles”. The url can be accessed through the link element, with the href attribute.
Finally to extract the main data, analyze the final page again.
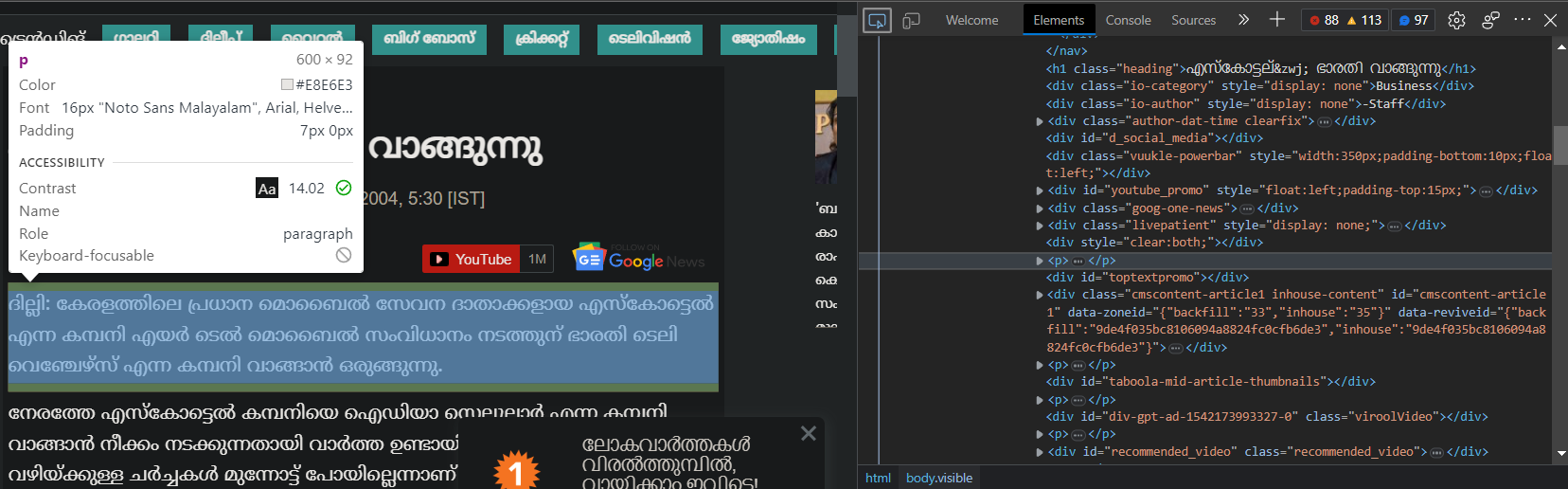
The main data is in the <p> tags of the article. So we can utilize the following code to extract the necessary information and save them to a local file.
news_html = requests.get(news_url).content
news_soup = BeautifulSoup(news_html, features="html5lib")
for elem in news_soup.findAll("p"):
doc_data += str(elem).replace("\n", "")
data.append(doc_data)
Finally put together the whole thing together and create a function as follows.
def get_data(url, lang, save_dir):
url = url.replace("language", lang)
end_date = date.today()
start_date = date(2000, 5, 1)
data = []
for single_date in daterange(start_date, end_date):
url_end = single_date.strftime("%Y-%m-%d").replace("-", "/") + "/"
page_url = url + url_end
for elem in main_soup.findAll("ul", attrs={"class": "dayindexTitles"}):
if elem.a:
doc_data = ""
news_url = url + elem.a.attrs["href"]
news_soup = BeautifulSoup(
requests.get(news_url, headers=header).content, features="html5lib"
)
for elem in news_soup.findAll("p"):
doc_data += str(elem).replace("\n", "")
data.append(doc_data)
Conclusion
Therefore our code is capable of extracting data from this website. The entire project code is available on GitHub. In the entire project, I have added some sanity checks and extended the functionality to a CLI, but the base logic of the scraping part remains the same.